概述
实际上将之前 policy iteration 当中基于模型的部分只要替换掉不需要模型的部分,就得到了本节课的蒙特卡洛的算法;另外在本门课当中将 value iteration 和 policy iteration 统称为 model-based reinforcement learning,更准确的说应该称为动态规划的方法。
这种方法研究的是比如用数据估计出来一个模型,然后再基于这个模型来进行强化学习。
而这节课讲的将是 model-free 的方法。
课程大纲:

会介绍基于 蒙特卡洛 思想的三个算法,三者环环相扣,另外第一个是最简单的,以至于简单到没办法用,但其是后面两个算法的基础。
Motivating example
从 model-based 的 RL 到 model-free 的 RL ,最让人难以理解的应该是怎么样在没有模型的情况下去估计一些量,而这里有一种重要的方法或者思想就是 蒙塔卡洛估计:

对于上面的抛硬币例子,使用 model-based 方法非常简单:

但有一个问题是,很有可能我们是没办法去知道这么详细准确的概率分布的,那么 model-free 的方式怎么做:

如上图所示,其基本的思想就是投掷硬币很多次,做很多次实验或者得到很多的采样,然后把所有的这些采样求它的平均数,而这就是 蒙特卡洛 的基本思想。
一个问题,使用这种方式得到的期望值是否精确:
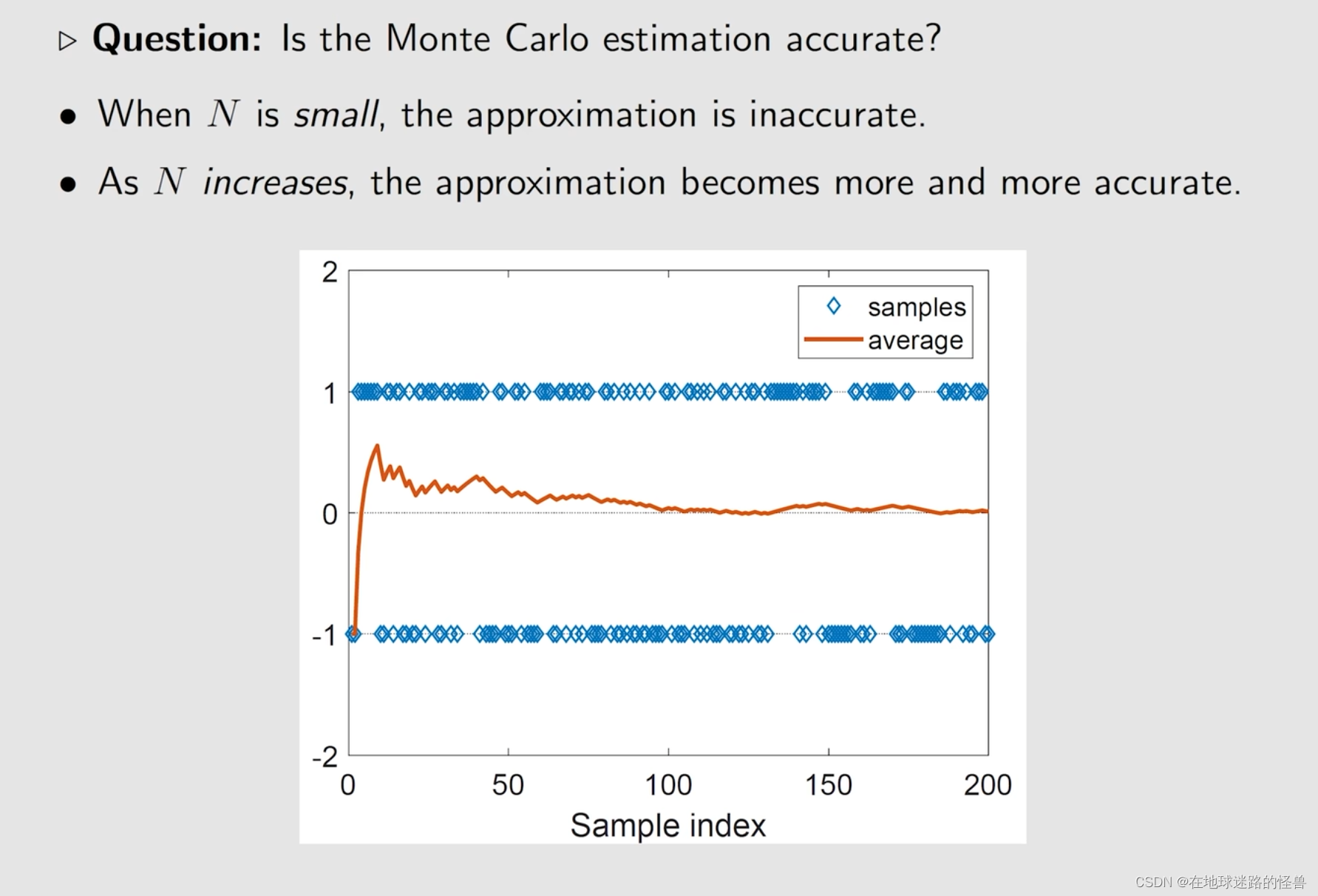
这种直观的解释事实上是有很好的这个数学来做支撑的,也就是大数定理:

可以总结出如下几点:

蒙特卡洛不仅仅可以用到这种投掷硬币这样简单的任务当中,凡是需要做大量的采样然后实验然后最后用实验的结果来进行近似的这样的一种方法,都可以称为 蒙特卡洛 的估计的方法。
The simplest MC-based RL algorithm
Algorithm:MC Basic
重点:

如何使得 policy iteration 这个算法变成 model-free 的:


如何求解?
首先从任意的一个 s 和 a 的一个组合出发,然后根据当前的策略我们可以完成一个 episode。我们计算出来这个 episode 的所对应的 discounted return 用小写的 g( s, a ) 来表示,这个 g( s, a ) 就是 action value 定义式中的 G(t) 随机变量集合中的一个采样,如果我们有很多这样的采样也就是一个采样集合,我们就可以使用这些采样求一个平均值来估计这个 G(t) 的这个平均值,也就是这个 G(t) 的期望:

总的来说就一句话:当我们没有模型的时候,我们就得有数据,没有数据的时候就得有模型。
这里的数据在统计或者概率里面称为 sample,而在强化学习当中被称为 experience 。
给出详细定义:

实际上不难看出,该算法和 policy iteration 实际上是差不多的,第二步是一模一样的,唯一的区别在第一步:policy iteration 第一步求解 state value 然后再得到 action value,而 MC Basic 算法则是直接通过数据得到这个 state value 。
算法的伪代码描述:

这个算法实际上在其他地方是看不到的,这是赵世钰老师自己为了方便教学给单独命名的一个算法,因为老师认为在学习的时候应该把最最核心的想法和其他让它看起来更加复杂的这样一些东西给剥离开来。而对于蒙特卡洛算法来说,其最核心的想法就是把 policy iteration 当中的基于 model 的部分替换掉。但是怎么样去更高效的利用这些数据则是后面两个算法需要做到并且提高的事情。
关于这一小节需要注意的事情:

应用例子:
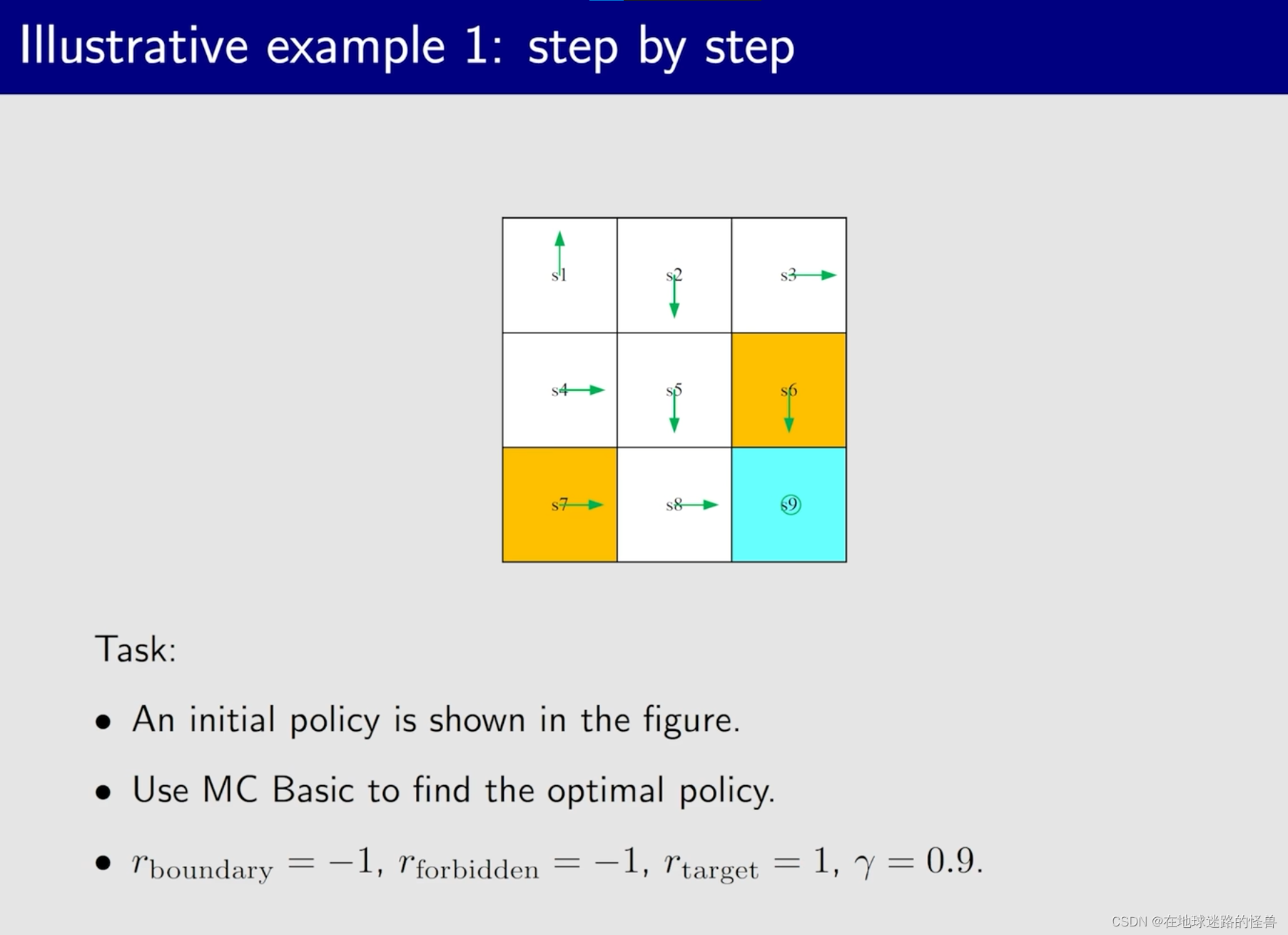





然后是第二个例子,重点是分析一些有趣的性质,如 episode 的长度:

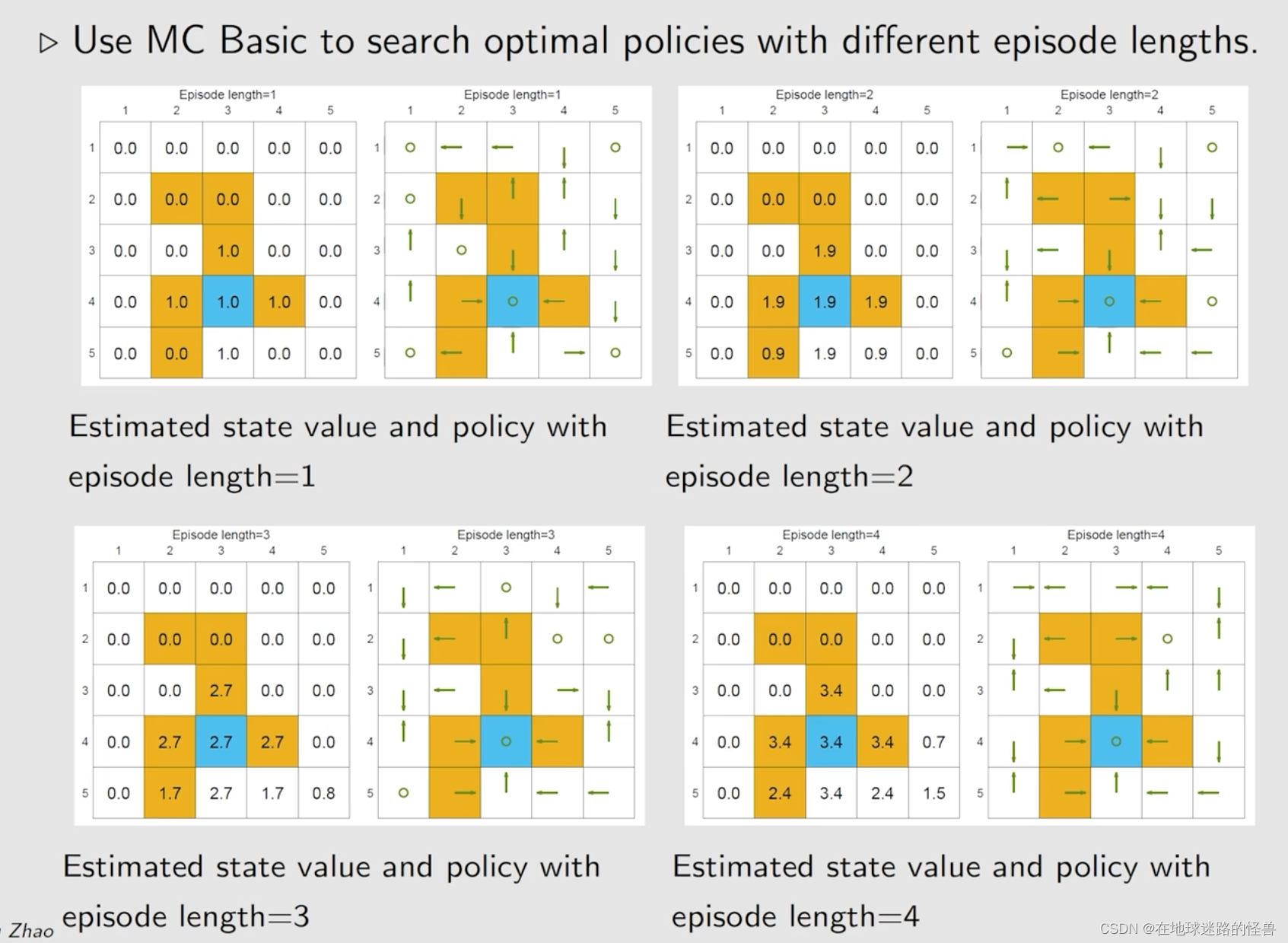
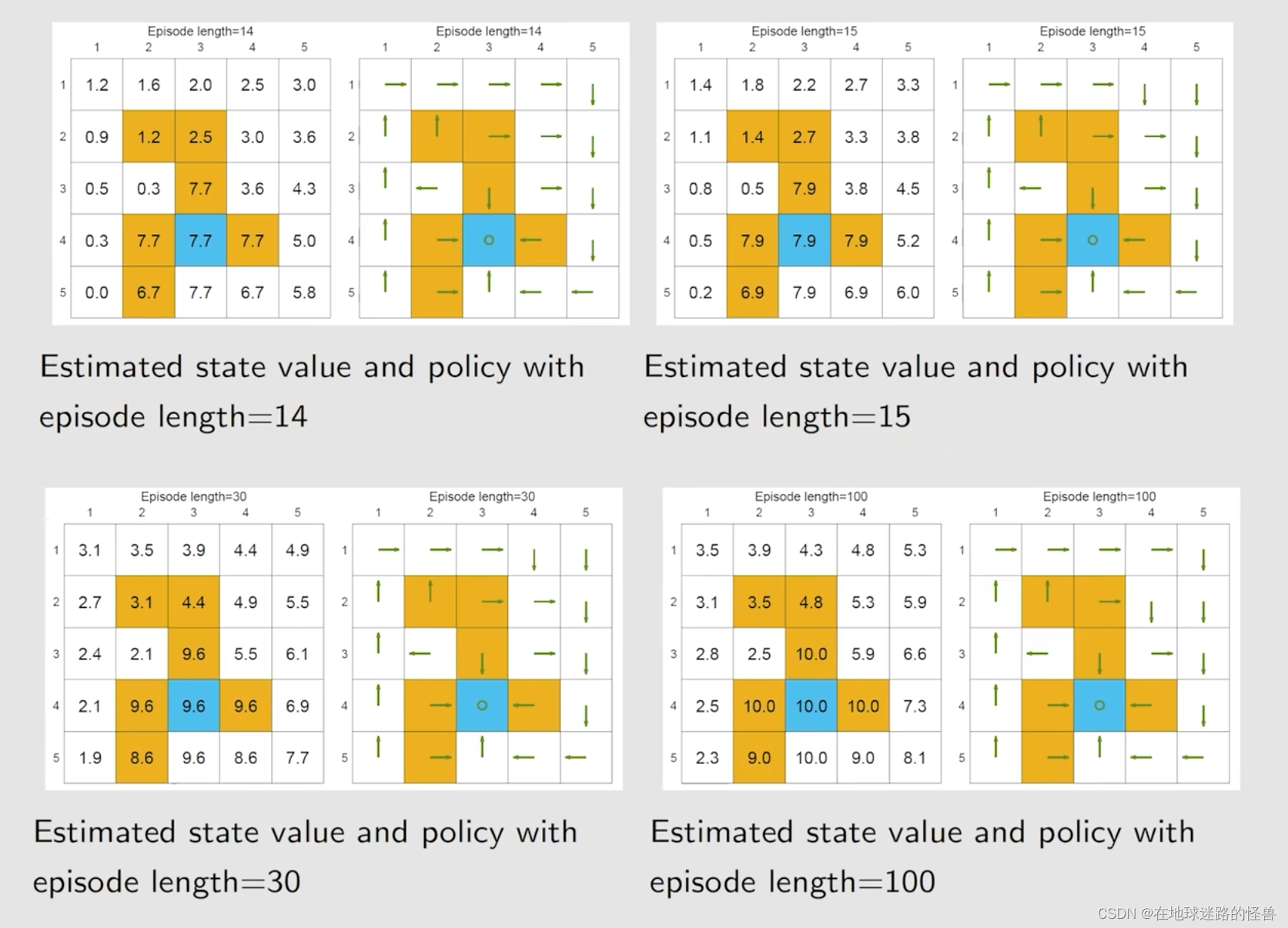
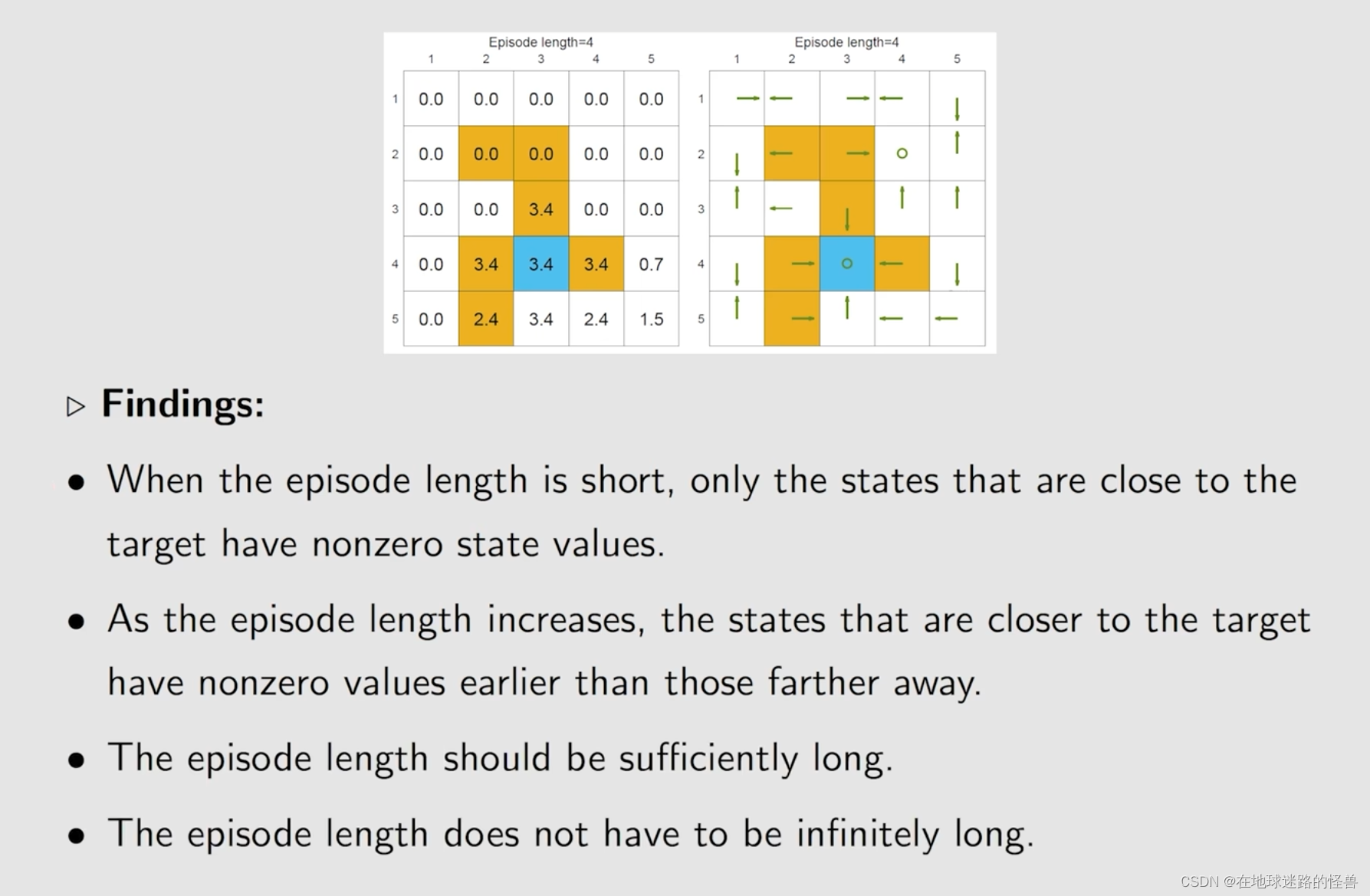
总结一下 episode 相关的性质:
Use data more efficiently
Algorithm:MC Exploring Starts





上述这些方法实际上有一个名字,叫 Generalized policy iteration,简称 GPI。
其不是一个具体的算法,而是一大类算法,或者说它是一种思想或者架构,就是在 policy evaluation 和 policy improvement 中间不断地进行切换,而且这个 policy evaluation 不需要去非常精确地把 action value 或者 state value 给估计出来。
之前介绍的算法和本节课学习的算法实际上都能够落到这个 GPI 的框架当中。
基于上面的思想,我们就可以得到一个新的算法,称为 MC Exploring Starts ,算法伪代码:


然而这个算法的理论和实际是割裂的,因为在实际当中非常难实现,比如在一个网格世界当中要有一个机器人在那里,它要从不同的 (s, a) 出发的时候,我们必须得给它搬运过去设置好程序等等会比较麻烦。因此我们是需要将 exploring starts 这个条件给去掉或者说叫转化掉的,而在下一小节中所介绍的算法中我们可以做到这个事情。
MC without exploring starts
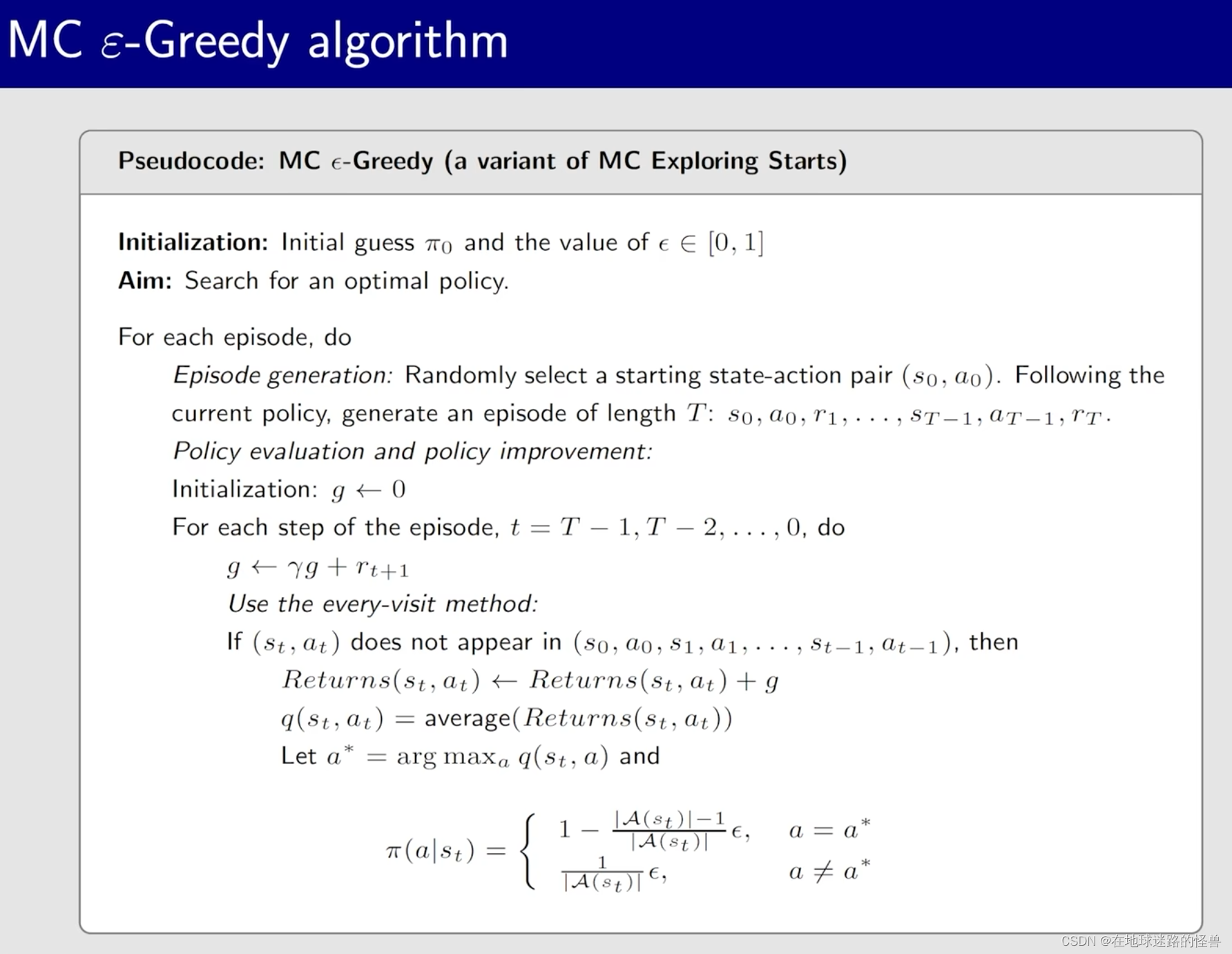
Algorithm:MC ε-Greedy
去掉 exploring starts 的方法就是引入 soft policy:


exploitation 字面意义上是“剥削”,但是在强化学习中应该被理解为 “充分利用” 的意思。
那么如何将这种策略和我们之前说的蒙特卡洛的强化学习问题结合在一起呢?
先看我们之前的方式:

而现在的做法也很简单:

算法伪代码如下:
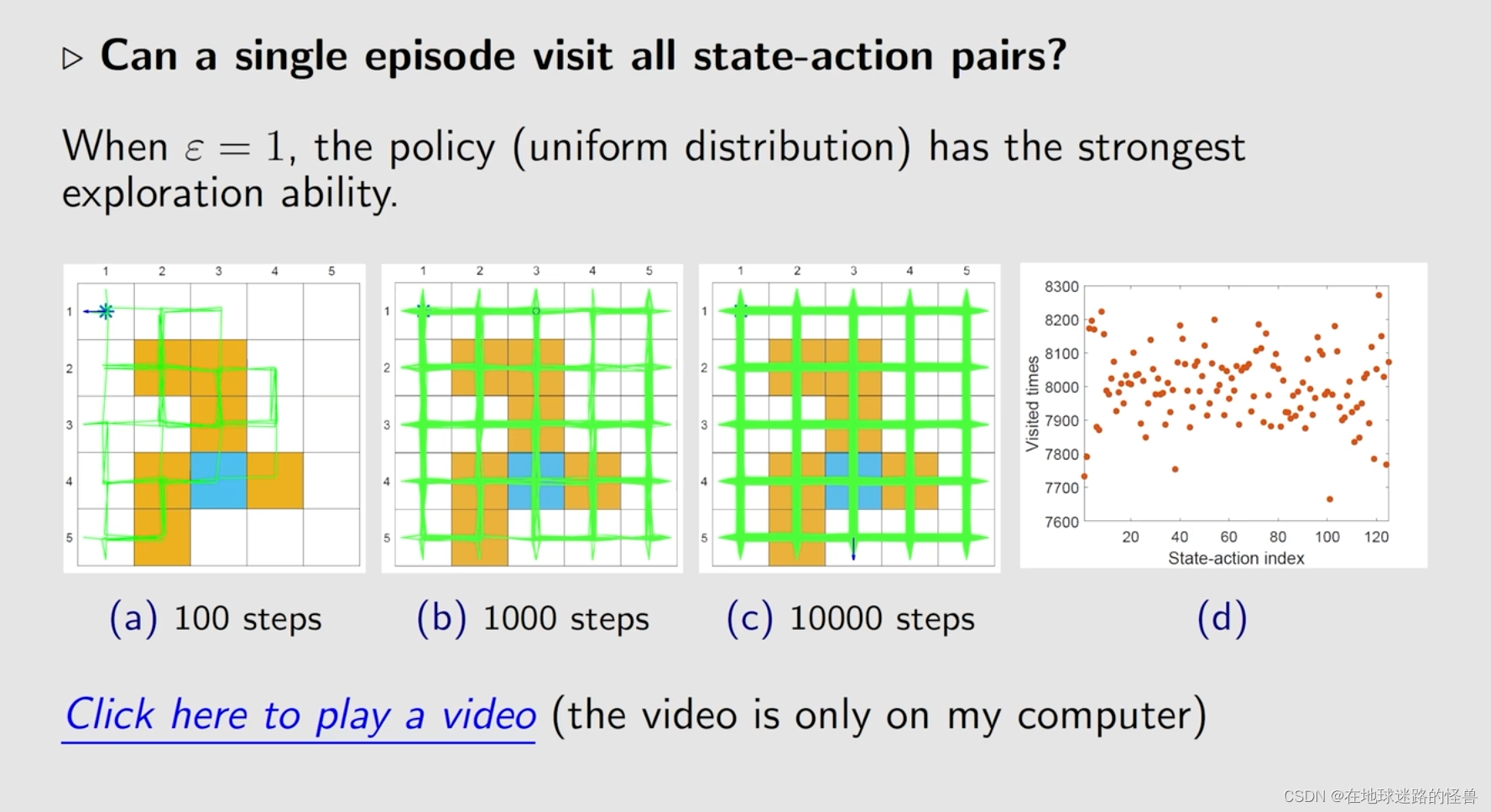
一些例子,用来更好的理解这个算法:
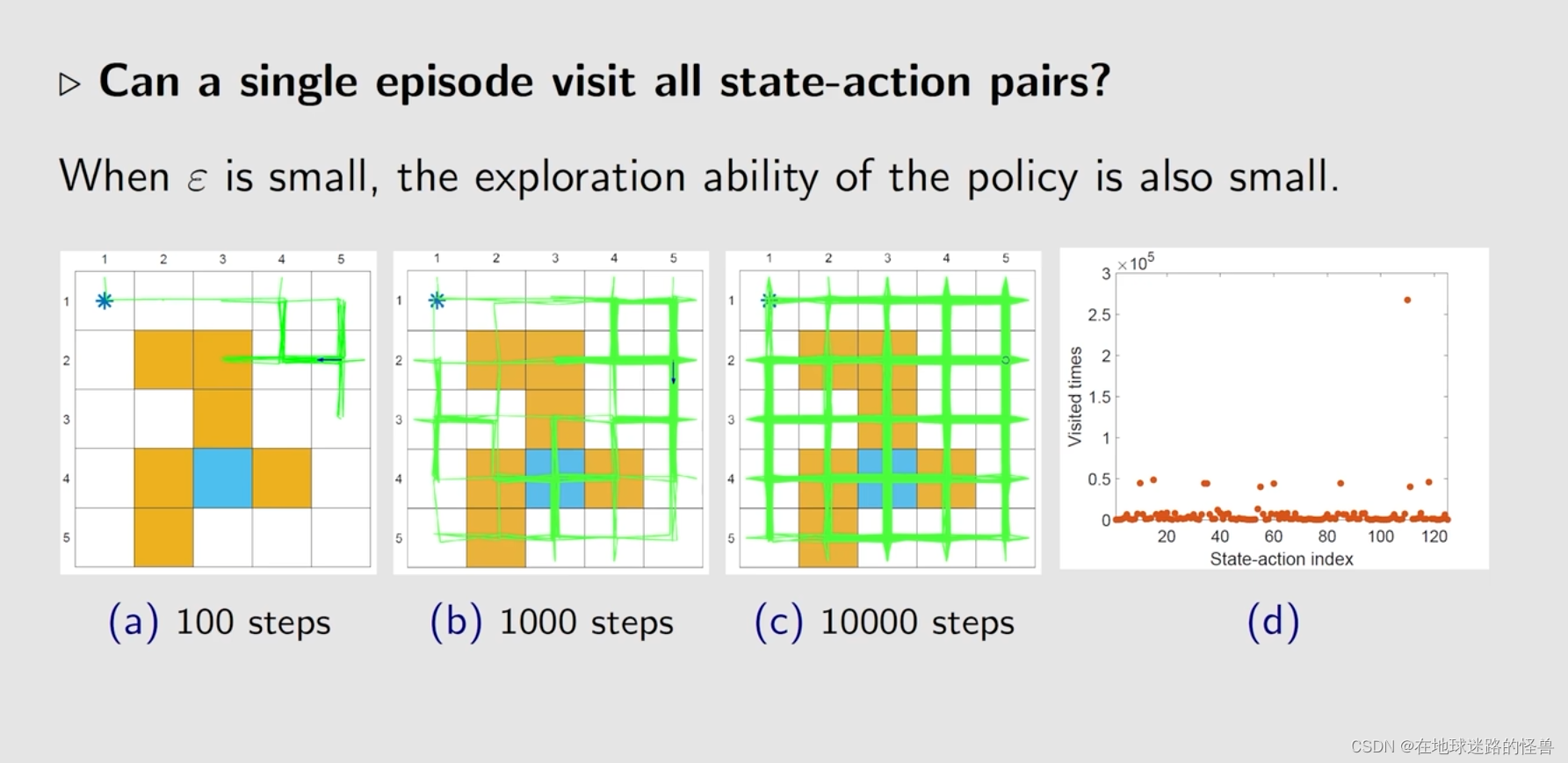


一个技巧就是,最开始的时候 ε 可以设置大一点,这个时候探索性比较强,然后 ε 就可以逐渐减小到 0,最后就可以得到一个最优的策略。
Summary